Local and Controllable LLMs#
This is a relatively simple guide for hosting your own local LLM through an API (ollama w/llama.cpp) to access it by different helper functions, including the necessary basics to understand how models can work as “tools” (commonly called tool use) and for controllable generation.
The goal here is to use smaller models that fit on our laptops to perform useful tasks, something you may have thought to be requiring cloud services or APIs from e.g., anthropic or openai.
Most of the tasks in real-world applications and sciency stuff requires control over what kind of outputs we get from a model.
Let’s say you want to generate a synthetic dataset. You expect a certain amount of columns for each data point. What if you want to create a recipe website from data you have gathered from numerous sources? You would like to structure the raw text as a specific and predictable format. The same goes for calling tools, such as a weather API, where you would first define a function in your program to call the API, but make the LLM generate the necessary input from natural language, and, more importantly, which function to call.
Today there’s a lot of available libraries to solve this, but they often contain far more than they need to, when we really just want to get started with generating some output. A very thorough library for controlling your output or programming LLMs is DSPy (Declarative Self-improving Python) by StanfordNLP, or LangChain.
Here is a snippet of some of the requirements from DSPy:
Requirements and some dependencies for DSPy.
What we want:
A model small enough for a laptop (
<16GB) served through an APIA system for handling and orchestrating responses
Something useful you can use in your master’s thesis, perhaps!
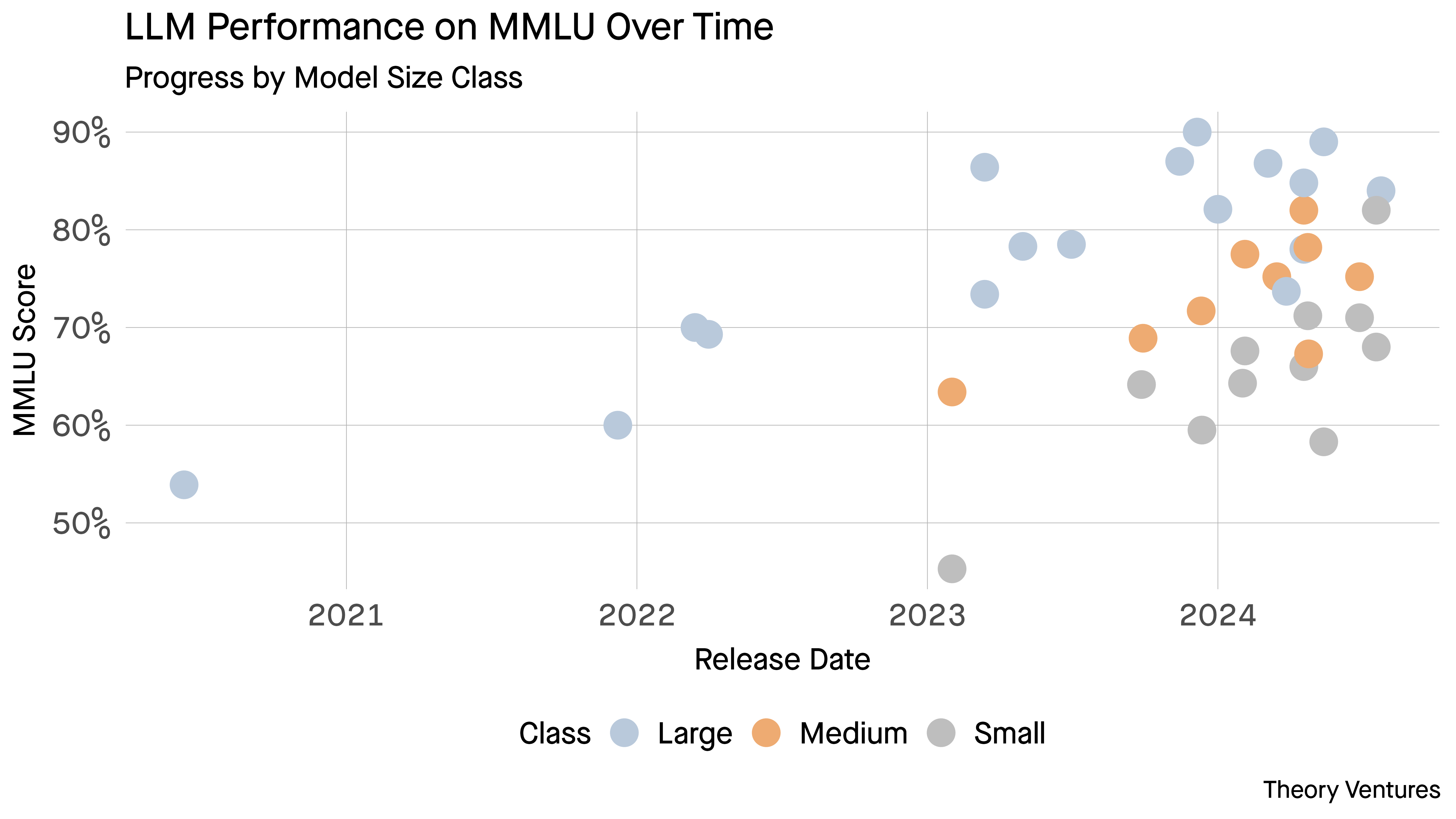
Also… It’s not only cheaper. It’s much, much faster (https://tomtunguz.com/small-but-mighty-ai/)
Llama Model |
Observed Latency per Token |
|---|---|
7B |
18 ms |
13B |
21 ms |
70B |
47 ms |
405B |
70-750 ms |

a local llama (probably)
Generated with FLUX.1 [schnell] 8-bit, 6.5GB on a macbook.
Prompt: a portrait pencil sketch of a cool llama with sunglasses, wearing a sweater saying "LOCAL and CONTROLLABLE", minimalist, impressionism, negative space